消息队列服务Kafka揭秘 痛点、优势及在信息系统集成中的适用场景
引言
在当今数据驱动与微服务架构盛行的时代,系统间的可靠、高效通信成为关键。Apache Kafka,作为一个分布式的流数据平台,已从最初的日志聚合系统演变为企业级消息队列和流处理的核心组件。本文将深入揭秘Kafka,剖析其核心特性、常见痛点、独特优势,并重点探讨其在信息系统集成服务中的典型应用场景。
一、Kafka核心概念揭秘
Kafka本质上是一个高吞吐量、分布式、基于发布/订阅模式的消息系统。其核心架构围绕几个关键概念构建:
- 主题(Topic):消息发布的类别或名称,生产者向特定主题发送消息。
- 分区(Partition):每个主题可以被分为多个分区,实现数据的并行处理与水平扩展,是Kafka高吞吐量的基础。
- 生产者(Producer):向Kafka主题发布消息的客户端。
- 消费者(Consumer):订阅主题并处理消息的客户端。消费者可以组成消费者组(Consumer Group)以实现负载均衡。
- 代理(Broker):Kafka集群中的单个服务器节点,负责存储和转发消息。
- 偏移量(Offset):分区内每条消息的唯一标识,消费者通过管理偏移量来控制消费进度。
二、使用Kafka可能面临的痛点
尽管功能强大,但在采用Kafka时也需正视其复杂性与挑战:
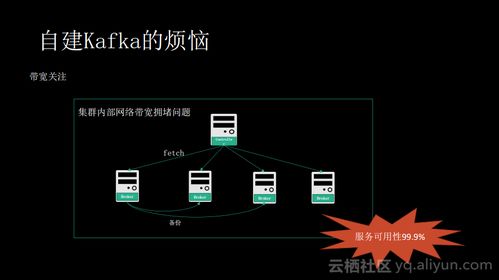
- 系统复杂性高:集群的部署、配置、监控和维护需要专业的知识和经验。分区、副本、ISR(In-Sync Replicas)等概念增加了运维复杂度。
- “Exactly-Once”语义实现复杂:虽然Kafka提供了事务支持以实现精确一次处理,但其配置和使用相对复杂,对应用设计和开发者有较高要求。
- 资源消耗:为了追求高性能,Kafka通常需要配置较多的内存和磁盘I/O资源。海量数据积累下的存储成本与清理策略需要精细规划。
- 客户端生态与版本兼容性:不同语言的客户端成熟度不一,且Kafka版本升级时,客户端与Broker之间的兼容性问题可能带来升级风险。
- 不适合低延迟或极小消息场景:Kafka为高吞吐优化,在毫秒级以下的极低延迟需求,或消息体极小的场景下,其优势可能不明显,反而显得笨重。
三、Kafka的突出优势
正是以下优势,使得Kafka在众多消息中间件中脱颖而出:
- 高吞吐量与可扩展性:通过分区机制,可以线性地通过增加Broker来提升处理能力,轻松支持每秒数百万条消息的吞吐。
- 持久化与高可用:消息持久化存储在磁盘,并可通过多副本机制实现故障自动转移,数据可靠性极高。
- 优秀的水平扩展能力:集群可以无缝扩展,新增节点无需停机,分区也可以重新分配以平衡负载。
- 多订阅者与消息回溯:基于偏移量的消费模型,允许同一消息被多个独立的消费者组重复消费,也支持消费者灵活地重置偏移以重新处理历史数据。
- 流处理集成:与Kafka Streams或KSQL等原生流处理库紧密结合,能够构建从数据接入、流转到实时处理的完整流水线。
四、在信息系统集成服务中的适用场景
信息系统集成旨在连接异构系统,实现数据与业务流程的互通。Kafka在其中扮演着“中枢神经系统”的角色,适用于以下场景:
- 异步解耦与数据管道:
- 场景描述:前端应用、后端微服务、数据库、数据仓库等系统需要松耦合通信。
- Kafka应用:作为统一的数据总线,生产者(如订单服务)将事件(如“订单创建”)发布到特定主题。多个消费者(如库存服务、物流服务、分析服务)异步订阅并处理,系统间不直接依赖,提升了整体架构的弹性与可维护性。
- 日志聚合与集中监控:
- 场景描述:分布式系统中,各服务实例的日志分散,难以进行统一的分析和监控。
- Kafka应用:各服务将日志作为消息推送至Kafka集群。下游可以连接Elasticsearch进行日志检索,或连接Flink/Spark Streaming进行实时错误告警和业务指标计算,实现高效的运维监控。
- 事件溯源与变更数据捕获(CDC):
- 场景描述:需要跟踪业务实体(如用户账户、商品库存)的状态变化历史,或将数据库的变更实时同步到其他系统(如搜索索引、缓存)。
- Kafka应用:业务服务将状态变更作为领域事件发布。或使用Debezium等工具将数据库的binlog实时捕获并流入Kafka。Kafka成为所有变更事件的持久化日志,为系统重建状态、数据同步提供可靠源。
- 流式数据处理与实时分析:
- 场景描述:需要对连续产生的数据流进行实时处理,如实时仪表盘、实时推荐、反欺诈检测等。
- Kafka应用:作为流数据的源头和传输通道。数据实时写入Kafka,下游的流处理引擎(如Kafka Streams, Apache Flink)进行窗口计算、聚合、模式匹配等,结果可再写回Kafka或存入其他系统,支撑实时决策。
- 流量削峰与缓冲:
- 场景描述:在促销、秒杀等场景下,前端请求量瞬间暴增,远超后端处理能力。
- Kafka应用:将瞬时涌入的请求或消息快速接入Kafka,利用其高吞吐和持久化能力缓冲压力。后端消费者按照自身处理能力匀速消费,避免了系统被突发流量冲垮,保障了最终的业务处理。
###
Apache Kafka凭借其分布式、高可靠、高吞吐的架构,已成为现代信息系统集成和实时数据管道的事实标准之一。选择Kafka,意味着选择了一套能够应对海量数据流、支撑复杂业务解耦、并赋能实时业务的强大基础设施。其引入的运维复杂性和技术门槛也不容忽视。因此,在决定采用前,需紧密结合业务对数据一致性、延迟、吞吐量的具体要求,并评估团队的技术储备与运维能力,从而让Kafka在恰当的场景下发挥最大的价值,真正成为驱动数字业务的流数据中枢。
如若转载,请注明出处:http://www.heimakuangyou.com/product/35.html
更新时间:2026-06-19 11:30:33